数据归集 6 月探查实录:三天三件事,把树形接口、数据脏坑、跨源机制全部扒一遍
把六月的”理所当然”全部扒开看一遍,结果挖出 5 个数据地雷、3 套接口改造方案、和 1 张被历史迁移搞脏的组织架构表。本文用三天三件事的实录方式,把树选择器大改造 → 接口对接与脏数据逻辑 → 跨源机制与文档/代码对账完整记录下来,每一节都附证据链(SQL、commit、commit message、API 验证结果),让没参与的同学也能照着复现。
🎧 文章导读
🎵 背景音乐
🎬 视频集(4 段 6 秒概览)
4 段 6 秒 AI 生成视频,分别对应”开场 → 6/1 树选择器 → 6/2 接口对接 → 6/3 数据地雷”。配合 BGM 食用更佳。
🎞️ 1. 开场:数据流(intro-flow)
开场动效——光数据在玻璃管道中流动
🎞️ 2. 6/1 树选择器生长(tree-growth)
6/1 主题——从单根到多分支的树形结构生长
🎞️ 3. 6/2 接口对接(api-contracts)
6/2 主题——API 文档卡片漂浮连接
🎞️ 4. 6/3 数据地雷(data-mines)
6/3 主题——5 个警告三角在暗夜中脉冲
写在前面:为什么是”探查实录”
数据归集系统是广东水文项目的核心模块,承担着把测站、设备、视频、流域、行政区多源数据按树形结构对外暴露的职责。2026 年 5 月 21 日,我们刚把”从 Redis 读 GZIP JSON”重构为”直连数据库 + 多数据源路由”(参见上一篇博客《树结构选择器:从 Redis 到直连数据库的架构重构》),6 月 1 日就接到了新的需求:前端要 type 字段、加过滤接口、调整接口签名。
本以为这只是几次小迭代,结果三天里越扒越深:
- 6/1:树选择器大改造、发现 148 个孤儿设备、把”所有流域”虚拟壳拆掉
- 6/2:写接口对接文档、设备类型筛选接口、负一级河流的来源追到上游数据
- 6/3:本以为”探查”可以收尾,结果挖出 5 个数据地雷——组织架构、跨源机制、注解不一致、设备类型污染、公司表脏数据
这篇博客的目的不是炫耀”挖了多少坑”,而是给后来者一份证据齐全的复现手册——所有的发现都附 SQL、commit、commit message 和 API 验证结果,遇到相同问题的同学可以照着查。
全文约 12000+ 字,配 5+ 张图、1 段导读音频、1 段背景音乐。建议收藏后分段阅读。
一、6 月 1 日:树选择器大改造
1.1 起点:5 月改造后的第一次回访
5 月 21 日那波改造(参见 《树结构选择器:从 Redis 到直连数据库的架构重构》)的成果是:
- 把
riverBasinTree等 12 个 tree 接口从 Redis 缓存的 7MB JSON 改为按需直连数据库 - 引入了 baomidou-dynamic-datasource 做多数据源路由
- 通过
setTreeNodeType()给节点打上type字段
6 月 1 日早上,用户反馈:
equipmentTreeFilteredByBasin返回的树不全,6 个根流域都”消失”了- 前端要 4 个
*Filtered接口的节点带type字段 - 想把”所有流域”这个壳去掉,让 7 个根流域直接并列
三件事都安排在同一天开工。看起来是三个独立任务,但做完发现它们互相纠缠——type 字段的实现路径要从 5/21 改造的代码里复用,”所有流域”壳拆掉后又反过来影响 equipmentTreeFilteredByBasin 的数据呈现。
1.2 第一件事:审查 6 个新提交的接口
早上 9 点开工,第一件事是审查前一天 commit 的 6 个新接口:
| 接口 | 类型 | 状态 |
|---|---|---|
stationTreeFiltered |
行政区测站过滤 | 新 |
equipmentTreeFiltered |
行政区设备过滤 | 新 |
stationTreeFilteredByBasin |
流域测站过滤 | 新 |
equipmentTreeFilteredByBasin |
流域设备过滤 | 新 |
stationList |
分页查所有测站 | 新 |
stationEquipmentList |
测站设备树 | 新 |
挨个 review 后发现 3 个问题:
问题 1:4 个 *Filtered 接口跟原接口功能完全重复
equipmentTreeByBasin 末尾已经调了 pruneEmptyBranches,这个方法实际上做了 filterTreeByLeafType 等价的事——按叶子节点类型剪枝。那么新加的 equipmentTreeFilteredByBasin 等于把”过滤”逻辑写了两遍。
1 | // equipmentTreeByBasin 末尾 |
问题 2:stationList 缺 3 个防护
- 没加
USFL=1过滤——会返回已删除的测站 - 没加
size > 0下界保护——pageSize=0时 MyBatis-Plus 行为未定义 - 没显式
select(...)列——返回全表字段,性能浪费
问题 3:stationEquipmentList 排序不稳定
1 | Map<String, List<StStbprpB>> map = stations.stream() |
前端拿到的设备列表每次顺序都不一样,调试时同事以为是 bug。
修复建议(已加入 P1 待办):
equipmentTreeFilteredByBasin跟equipmentTreeByBasin功能重复 → 删一个stationList加USFL=1过滤 +size > 0校验 + 显式 select 列stationEquipmentList加USFL=1过滤 + 改用LinkedHashMap::new保证顺序
[!warning] 经验教训
写新接口前先看一下底层方法是否已经做了相同的事。下次写*Filtered之前必须 reviewpruneEmptyBranches的实现。
1.3 第二件事:紫洞设备丢失问题排查(5 步定位)
接下来是当天的”重头戏”——用户反馈 equipmentTreeFilteredByBasin 返回的树只有 1 个根流域(珠江三角洲),其他 6 个根(西江、HB、HC、HE1A、816、817)整条被剪光,紫洞设备也丢了。
1.3.1 排查过程
第一步:怀疑调用链有问题
最初以为 equipmentTreeFilteredByBasin 跟 riverBasinTree 调用链不一致,绕了一圈发现两者都从 getRiverBasinTree() 开始拿完整树,只是 equipmentTreeByBasin 多走了 5 步(attachStationsToBasinTree → pruneEmptyNodes → attachEquipmentsToStationTree → pruneEmptyBranches → filterTreeByLeafType)。
第二步:实际请求 7 个根看差异
用 Python 调两个接口对比:
1 | # riverBasinTree: all 下 7 个根 |
第三步:定位到 pruneEmptyBranches 剪枝函数
1 | private boolean pruneEmptyBranches(TreeNode node) { |
pruneEmptyBranches 是向上传染的:一个测站没设备 → 删测站 → 整个子流域空 → 删子流域 → 父流域空 → 删父流域 → … 一路传到根。
第四步:查 7 个根的测站数和设备数
| 根流域 | 测站数 | 设备数 | 在 equipment 树中 |
|---|---|---|---|
| HA 西江流域 | 104 | 0 | ❌ |
| HB | 185 | 0 | ❌ |
| HC | 144 | 0 | ❌ |
| 812_813 珠江三角洲 | 195 | 18 | ✅ |
| HE1A | 137 | 0 | ❌ |
| 816 | 111 | 0 | ❌ |
| 817 | 170 | 0 | ❌ |
6 个根整条被剪掉是因为它们的测站全部没有非 VD 设备。问题变成了”为啥这么多测站没设备”。
第五步:直接查数据库找紫洞
用 MySQL MCP 查 bs_sw_cy_dh_equipmentb:
1 | SELECT * FROM bs_sw_cy_dh_equipmentb WHERE eqnm LIKE '%紫洞%'; |
找到了!紫洞作为设备存在,但 STCD 是空字符串。 equipmentTreeByBasin 按 STCD IN (stcds) 查询时空 STCD 匹配不上,所以这个设备被遗漏。
1.3.2 扩大排查
1 | SELECT COUNT(*) AS total, |
148 个设备 STCD 为空——这才是 equipment 树”数据不全”的真正原因。
1.3.3 按 EQTP 分布
| EQTP | 数量 |
|---|---|
| HADCP-水平式ADCP | 63 |
| FWQ-浮子水位计 | 37 |
| RDV-电波流速仪 | 34 |
| RWG-雷达水位计 | 7 |
| BWG-气泡水位计 | 3 |
| PWG-压力水位计 | 2 |
| 在线H-ADCP | 1 |
| HADCP-RDV | 1 |
都是真设备,不是 VD 视频设备。
1.3.4 根因与修复
数据问题,不是代码 bug:
bs_sw_cy_dh_equipmentb表中 148 个设备的 STCD 字段为空equipmentTreeByBasin按 STCD 关联测站和设备,STCD 空就匹配不到- 这些孤儿设备集中在 6 个根流域,导致这 6 个根在 equipment 树里整条消失
- 紫洞(VV81303560)是 148 个之一,还附带一个前导空格的小问题
推荐修复方式:补数据
1 | -- 候选查询:找出每个孤儿设备可能的测站 |
不推荐修复方式:改代码做模糊匹配
让 equipment 树对 STCD 为空的设备做名称匹配,会引入不确定性。数据问题应该用数据方式解决。
[!tip] 踩坑教训
- “数据对不上”先用 MCP 查库,不要在 HTTP 接口上绕。这次在接口之间绕了 4 轮才发现 148 个孤儿设备,直接 SQL 查 1 分钟就能搞定。
queryChild为 null 不可信——行政区和流域节点的queryChild都是 null,前端无法靠这个区分(这正是后来加type字段的动机)。- 看表数据时要看全貌——只查 1 个”紫洞”看到 STCD 空,应该立刻问”还有多少个 STCD 是空的”,否则会陷入”修一个又发现一个”的循环。
- 148 这个数字是个红旗——6 个根流域的 851 个测站全部没设备,这比例异常,肯定是数据问题不是代码问题。
1.3.5 紫洞设备排查路径总结
图 1-1:紫洞设备丢失问题的 5 步排查路径
1.4 第三件事:TreeNode 加 type 字段
下午 14:00,前端反馈现有 tree 接口返回的节点类型不明确:
| 节点 | queryChild |
推断方式 | 可靠性 |
|---|---|---|---|
| 行政区 | null |
不可区分 | ❌ |
| 流域 | null |
不可区分 | ❌ |
| 测站 | {sttp, rvnm, addvcd} |
含 sttp |
✓ |
| 设备 | {eqtp, symbol, model, stcd} |
含 eqtp |
✓ |
痛点:行政区和流域的 queryChild 都是 null,前端无法靠 queryChild 区分;queryChild 推断还容易受字段扩展影响。
1.4.1 设计
类型映射:
| 值 | 含义 | 节点示例 |
|---|---|---|
| 0 | 未知/非业务节点 | 兜底值 |
| 1 | 行政区 | 省/市/区/镇 |
| 2 | 流域 | 根流域、子流域、合成节点(”所有流域”、”-1级河流”) |
| 3 | 测站 | 携带 sttp 的节点 |
| 4 | 设备 | 携带 eqtp 的节点 |
4 个接口的 type 链路:
| 接口 | 链路 |
|---|---|
stationTreeFiltered |
1 → 1 → 1 → 3 |
equipmentTreeFiltered |
1 → 1 → 1 → 3 → 4 |
stationTreeFilteredByBasin |
2 → 2 → 2 → 3 |
equipmentTreeFilteredByBasin |
2 → 2 → 2 → 2 → 3 → 4 |
1.4.2 实现
改动文件(最小化):
| 文件 | 改动 | 行数 |
|---|---|---|
TreeNode.java |
加 Integer type 字段 + Swagger 注解 |
3 |
TreeSelectorServiceImpl.java |
加 setTreeNodeType() 工具方法 + 4 处调用 |
~15 |
| Controller / Service 接口 | 不动 | 0 |
TreeNode 加字段:
1 | // gdsw-modules/algorithm-plugin-modules/algorithm-plugin-api/.../TreeNode.java |
打标逻辑:
1 | // TreeSelectorServiceImpl.java - 4 处调用 |
1.4.3 为什么打标位置这么选
- 行政区/流域树整体打 1/2:因为
getRegionTreeFromApi/getRiverBasinTree是整个树构建的入口,构完一次性递归打标最干净。 - 测站/设备节点创建时直接 set:因为
toStationTreeNode/toEquipmentTreeNode是单节点工厂方法,节点创建时 type 已知,直接 set 最简洁。 - 不动树构建过程:保留原有逻辑,只在结果上叠加 type,避免引入 bug。
1.4.4 验证
实际请求 4 个接口,确认 type 链路:
1 | { |
✅ 全部正确。
[!tip] 设计取舍
- 打标位置选择:选构树入口打标而不是逐节点 set,是因为 4 个
*Filtered委托给 4 个原方法,原方法里已经有”我知道这棵树是哪种类型”的上下文。在构树后统一打标,改动量最小、侵入性最低。- Type 0 兜底值:理论不会出现 type=0 的节点,但保留它作为”未知”标记,比让前端处理 null 更友好。
- 类型用 Integer 而不是 String:用户明确要数字编码,省字节、序列化快、前端 if/else 简单。
1.5 续:当天后续的 4 件事
加完 type 字段后,又搞了 4 件事。它们的来龙去脉又是另一个故事。
1.5.1 发现”所有流域”是后包出来的壳
用户在终端看到 7 条 未找到父节点: 节点 id=HA000000000E, PARENT_CODE='-1',将作为根节点处理 警告,问我什么意思。
排查后:
- 直接调第三方接口
getRiverBasinByCache拿到 1219 条记录 RVCD="all"或RVCD1="all"的记录数: 0- 7 个根流域的源数据
PARENT_CODE='-1'(业务约定的”无父”),互相独立,没有共同祖先 - “所有流域” 是
RiverBasinTreeUtil.buildTreeWithRoot在我们代码里凭空创建的壳(id=”all”,包了 7 个根当 children)
1 | // RiverBasinTreeUtil.java |
1.5.2 Tree 接口去掉”所有流域”壳(Plan 1 + Plan 2)
用户想”把 7 个根当成首节点”,不要中间那层壳。经历两个阶段:
Plan 1:只动 getRiverBasinTree
getRiverBasinTree 从 R<TreeNode> 改为 R<List<TreeNode>>,下游调用方用 getRiverBasinTreeWithRoot() 私有 helper 包壳(保持向后兼容)。改动小,但下游 6 个 tree 接口还是单根。
Plan 2:全栈改造
用户说”全栈改造”,我直接改了 12 个接口签名(包括行政区侧)。用户发现后回退 4 个行政区侧改动,明确说”管我行政区什么事情”。
最终:只动流域侧 6 个接口 + getTree 统一入口。
1.5.3 涉及改动
| 接口 | 改前 | 改后 |
|---|---|---|
riverBasinTree |
R<TreeNode>(所有流域壳) |
R<List<TreeNode>>(7 根) |
stationTreeByBasin |
R<TreeNode> |
R<List<TreeNode>>(按 rvcd 路由或多根处理) |
equipmentTreeByBasin |
R<TreeNode> |
R<List<TreeNode>> |
stationTreeFilteredByBasin |
R<TreeNode> |
R<List<TreeNode>> |
equipmentTreeFilteredByBasin |
R<TreeNode> |
R<List<TreeNode>> |
getTree?type=basin |
1 根 | 7 根 |
getTree?type=region |
1 根 | 1 根(包成单元素 list) |
stationTreeByRegion |
不动 | 不动 |
equipmentTreeByRegion |
不动 | 不动 |
stationTreeFiltered |
不动 | 不动 |
equipmentTreeFiltered |
不动 | 不动 |
1.5.4 循环内重复查询提到外面(性能优化)
用户发现 stationTreeByBasin 和 equipmentTreeByBasin 在循环里每次都查 DB:
1 | // 改前:7 次查询 |
queryAndGroupStationsByRvcd(keyword) 只依赖 keyword,不依赖 root——纯浪费。提到循环外。
equipmentTreeByBasin 也有同样问题(7 次设备查询),改成收集所有 stcds 后 1 次查完。
DB 查询次数对比:
stationTreeByBasinno-rvcd:7 → 1equipmentTreeByBasin:7 → 1
1.5.5 空根节点过滤
用户发现 equipmentTreeByBasin 返回 7 根但 5 根 children: [](空),要求过滤。
stationTreeByBasin 和 equipmentTreeByBasin 在循环末尾加:
1 | if (root.getChildren() != null && !root.getChildren().isEmpty()) { |
效果:equipment 树从 7 根降到 2 根(西江 + 珠江三角洲)。
1.5.6 惊喜发现:紫洞出现了
测试时发现紫洞(VV81303560)从无到有,出现在西江 → 北流河 → 杨梅河 → 潘内 下。说明 148 个孤儿设备中紫洞的 STCD 已经被补上。[[紫洞设备问题排查]] 里的 P0 数据问题已部分修复。
图 1-2:6/1 树选择器改造全景——type 字段 + 多根返回 + 性能优化
1.6 6/1 经验总结
[!tip] 三个”不要”
- 不要让用户多次澄清同一个问题——“你看 riverBasinTree 是对的” → “等下结构不对” → “你看西江” → “紫洞不是视频设备” → “你有数据库 mcp 吗”,AI 应该更早主动提出”我直接查数据库看吧”而不是被动等。
- 遇到”数据对不上”应该立即用 MCP 查,不要在 HTTP 接口上绕弯子。
- 询问时多给选择题,少让用户自由回答。比如”紫洞是设备还是测站?”这种歧义用
AskUserQuestion列表会更高效。- 批量查数据:查 148 个孤儿设备时,应该主动跑 SQL 列出前 20 个 + 按 EQTP 分布 + 按 stcd 关联的统计,而不是等用户问。
- 记笔记时主动整理:用户说”记录一下”时,可以自动生成 3 个文件(工作记录、问题分析、功能设计),而不是只写一个。
[!warning] 三个”应该”
- **”全栈”应该理解为”流域侧全栈”,不是”所有 tree 接口全栈”**——遇到模糊词要先问清楚范围。
- “用户是不是这个意思”要直说:用户最初说”全栈改造”,我应该问”是流域侧全栈还是所有 tree 接口”,而不是直接假设”全栈 = 所有”。
- 写新接口前先 review 底层方法——
pruneEmptyBranches已经做了”按类型过滤”的工作,新加的*Filtered接口是纯壳。
二、6 月 2 日:接口对接与数据逻辑说明
2.1 起点:6/1 改造的延续
6/1 的多根改造、type 字段、148 孤儿设备排查都有了结论,但还没完。6/2 上午,用户提了 3 个新需求:
- 写一个 对接文档给前端,让前端知道 6 个 List 接口怎么适配
- 加 2 个设备类型筛选接口(按行政区/按流域),方便前端做下拉框
- 解释 “-1级河流” 节点到底从哪来、为什么 SORT=999
3 件事预计 2 天,结果 1 天就搞完了——因为 6/1 的 type 字段、多根改造已经铺好了路,6/2 主要是文档和”代码澄清”。
2.2 第一件事:tree 接口改造对接说明
2.2.1 接口签名变化(破坏性)
6 个接口从 R<TreeNode> 改为 R<List<TreeNode>>:
| 接口 | 改前 data |
改后 data |
|---|---|---|
GET /dataCollection/riverBasinTree |
{id:"all", children:[...]} |
[{...HA}, {...HB}, {...HC}, {...812_813}, {...HE1A}, {...816}, {...817}] |
GET /dataCollection/stationTreeByBasin |
单根 | 1 根(带 rvcd)或 N 根(无 rvcd,过滤无测站的空根) |
GET /dataCollection/equipmentTreeByBasin |
单根 | 1 根(带 rvcd)或 N 根(无 rvcd,过滤无设备的空根) |
GET /dataCollection/stationTreeFilteredByBasin |
单根 | 1 根(带 rvcd)或 N 根(无 rvcd,过滤空根) |
GET /dataCollection/equipmentTreeFilteredByBasin |
单根 | 1 根(带 rvcd)或 N 根(无 rvcd,过滤空根) |
GET /dataCollection/tree?type=basin |
单根 | 7 根 |
GET /dataCollection/tree?type=region |
单根 | 1 根(包成单元素 list) |
行政区侧 4 个接口保持 R<TreeNode> 单根不变:
stationTreeByRegion/equipmentTreeByRegion/stationTreeFiltered/equipmentTreeFiltered
2.2.2 前端需要做的事
1. 适配 data 是数组的情况(必须)
1 | // 改前 |
涉及端点:riverBasinTree / getTree?type=basin / getTree?type=region / stationTreeByBasin / equipmentTreeByBasin / stationTreeFilteredByBasin / equipmentTreeFilteredByBasin。
2. 列表长度可能变少(重要)
无 rvcd 时,所有 4 个 basin 接口都会过滤空根,返回数量 N ≤ 7:
stationTreeByBasin:过滤无测站的根 → 返 N 根(N 取决于哪些根流域下有测站)equipmentTreeByBasin:过滤无设备的根 → 返 N 根(N 取决于哪些根流域下有设备)stationTreeFilteredByBasin:同上(过滤后再过滤空节点)equipmentTreeFilteredByBasin:同上- 带 rvcd 时固定返 1 个
前端不需要处理空对象了,根节点都是”有内容”的。
3. rvcd 路由保持兼容
1 | // 无 rvcd:返多根 |
前端逻辑可以这么写:
1 | const list = response.data; |
4. type 字段(已就绪)
每个节点都有 type 字段:
| 值 | 含义 | 示例节点 |
|---|---|---|
| 1 | 行政区 | 省/市/区 |
| 2 | 流域 | 根流域 + “所有流域” + “-1级河流” |
| 3 | 测站 | 携带 sttp 的节点 |
| 4 | 设备 | 携带 eqtp 的节点 |
冗余确认:type=3 等价于 queryChild 含 sttp;type=4 等价于含 eqtp。建议前端**只信 type**,不要反推 queryChild。
5. 行政区侧接口不变
stationTreeByRegion / equipmentTreeByRegion / stationTreeFiltered / equipmentTreeFiltered 这 4 个保持原样,data 还是单个对象。前端无需改。
2.2.3 提交清单(提交前必看)
- 前端已适配 6 个 List 接口(建议先让他们确认)
- 后端其他服务 没人调这 6 个接口(已 grep 确认只有 3 个内部文件)
- commit 但不 push,等 2-3 天缓冲
commit message 草稿:
1 | feat: 流域树接口改为多根List返回 + 缓存自愈 |
2.2.4 性能特征
| 接口 | 第一次(缓存空) | 后续命中 |
|---|---|---|
| 流域侧 4 个 *ByBasin / *FilteredByBasin | ~500ms(DB 兜底) | ~400-700ms |
| 行政区侧 4 个 *ByRegion / *Filtered | ~1500ms | ~500ms(缓存命中后) |
第一次访问 regionTree 慢 1500ms 是因为缓存空、调第三方。第二次起自动 ~500ms(自愈机制已写入 Redis)。
stationTreeByBasin / equipmentTreeByBasin 无 rvcd 时会过滤空根,返回数量 ≤ 7,前端按数组遍历即可。
2.2.5 Redis 缓存自愈
getRegionTreeFromApi 加了 5 行自愈代码:
1 | if (jsonStr != null && !jsonStr.isEmpty()) { |
- 写缓存独立 try-catch——Redis 挂了不影响主流程
- 数据格式跟
BasicDataTask一致(Base64(gzip)) - 缓存空会自动写,不需要定时任务
[!tip] 关键设计点
- 写缓存独立 try-catch——Redis 故障不影响主流程,下次仍会重试
- 数据格式跟 BasicDataTask 一致(gzip 压缩)——避免数据格式不一致导致的兼容问题
- 缓存空自动写——不需要单独定时任务,访问即触发
2.2.6 滚动升级风险
- 新接口 vs 老接口:因为是签名变更(不只是新增),需要前端先升级、后端再上线——或后端上线时前端暂时不能调这 6 个接口
- 建议:先 commit 不 push,前端确认适配后,再合并到 master
回滚方案:
1 | git revert HEAD # 一键回退 3 个文件 |
无副作用(改动自包含,没改公共 API 依赖)。
2.2.7 未完成项
- 148 个孤儿设备还有 147 个 STCD 空的没补(紫洞那个被补了)
BasicDataTask没触发的原因没查(因为不需要了——现在自愈)- WARN 日志噪音
未找到父节点: PARENT_CODE='-1'没修(业务约定的”无父”,代码当成查找 -1 父节点)
2.3 第二件事:设备类型筛选接口
前端先调这两个接口拿到设备类型列表做下拉筛选,再用 eqtp 参数调设备树接口过滤。
典型用法:不传参,直接拿全量设备类型列表。
2.3.1 接口列表
1. 按行政区获取设备类型列表
1 | GET /dataCollection/equipmentTypesByRegion |
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| addvcd | string | 否 | 行政区编码(前缀匹配),不传返回全量 |
| keyword | string | 否 | 设备名称关键词(模糊搜索) |
不传参调用:GET /dataCollection/equipmentTypesByRegion → 返回行政区全量设备类型(34 个)
2. 按流域获取设备类型列表
1 | GET /dataCollection/equipmentTypesByBasin |
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| rvcd | string | 否 | 流域编码,不传返回全量 |
| keyword | string | 否 | 设备名称关键词(模糊搜索) |
不传参调用:GET /dataCollection/equipmentTypesByBasin → 返回流域全量设备类型(6 个)
2.3.2 返回格式
1 | { |
返回 List<String>,已去重,可直接用于下拉筛选。
2.3.3 前端使用流程
1 | 1. 用户选择行政区/流域 |
2.3.4 实现说明
- 内部调的是已有的
equipmentTreeFiltered/equipmentTreeFilteredByBasin(eqtp=null拿全部设备) - 从返回的树结构中递归收集
type=4节点的queryChild.eqtp,去重后返回 - 行政区和流域返回的设备类型范围不同(流域过滤空根后范围更小)
2.4 第三件事:负一级河流逻辑说明
2.4.1 来源和含义
第三方流域数据接口(http://10.144.32.219:9981/thirdpartyApi/getRiverDataByCache)返回的原始数据中,上游数据本身就存在 5 个节点的 RVNM 为 **-1级河流**。
上游原始数据(已确认):
1 | { |
| 字段 | 值 | 说明 |
|---|---|---|
RVNM |
-1级河流 |
上游原始名称,不是代码造的 |
RV_LEVEL |
-11 |
全部 1219 条记录中,只有这 5 条是 -11,是特殊的级别标记 |
SORT |
999 |
上游数据本来就是 999,不是代码设的 |
PARENT_CODE |
812_813 |
指向真实父节点(珠江三角洲河网区) |
RVCD |
812_813_-1 |
格式为父节点 id + _-1 |
代码里 SORT_LAST_MARKER = "-1级河流" 只是排序标记,配合上游已有的 SORT=999 确保排最后,没有构造任何节点。
2.4.2 RV_LEVEL 分布
| RV_LEVEL | 条数 | 说明 |
|---|---|---|
| -11 | 5 | -1级河流 容器节点 |
| -1 | 174 | — |
| 0 | 95 | — |
| 1 | 372 | — |
| 2 | 357 | — |
| 3 | 195 | — |
| 4 | 21 | — |
2.4.3 具体例子:珠江三角洲河网区
以 珠江三角洲河网区(RVCD=812_813)为例,对比两种河流:
| 河流 | 节点 id(来自 RVCD1/RVCD) | 父节点 pid | 说明 |
|---|---|---|---|
| 茅洲河 | HD16C000000S |
812_813 |
上游分配了具体河流编码,直接挂在珠江三角洲下 |
| 深圳河 | HD16D000000S |
812_813 |
同上 |
| -1级河流 | 812_813_-1 |
812_813 |
上游造的分类容器节点,也是直接挂在珠江三角洲下 |
| 崖门水道 | HD2A0000000P |
812_813_-1 |
上游没给它分配具体分类,归到了 -1级河流 下 |
1 | 珠江三角洲河网区 (RVCD=812_813) |
关键区别:茅洲河和崖门水道都属于珠江三角洲,但上游数据的分类方式不同:
- 茅洲河:上游分配了具体河流编码(
HD16C000000S),父节点直接是珠江三角洲 - 崖门水道:上游没有分配具体分类,被归到了
-1级河流这个容器下,父节点是-1级河流(812_813_-1)
这些河流本身都是正常的(西江干流水道、磨刀门水道、虎门水道等都是珠江的重要水道),只是上游数据的一种分类习惯。
2.4.4 全部 5 个 -1级河流 节点
| 节点 id | 父节点 pid | 子节点数 | 所属流域 |
|---|---|---|---|
801_802_803_804_805_806_807_808_809_-1 |
801_802_803_804_805_806_807_808_809 |
1 | 韶关区域 |
812_813_-1 |
812_813 |
147 | 珠江三角洲河网区 |
815_-1 |
815 |
17 | 粤东沿海诸河 |
816_-1 |
816 |
1 | 粤西诸河 |
817_-1 |
817 |
1 | 海南岛 |
2.4.5 代码位置
文件:RiverBasinTreeUtil.java
1 | private static final String SORT_LAST_MARKER = "-1级河流"; // 第 172 行 |
2.4.6 用法:排序兜底
在 sortChildrenRecursively 方法(第 174-191 行)中,对每个节点的子节点排序:
1 | node.getChildren().sort((a, b) -> { |
排序规则:
| 情况 | 结果 |
|---|---|
| A 和 B 都不是 “-1级河流” | 按 dictSort 升序 |
| A 和 B 都是 “-1级河流” | 按 dictSort 升序 |
| A 是,B 不是 | A 排最后(return 1) |
| A 不是,B 是 | B 排最后(return -1) |
效果:”-1级河流”节点始终排在同一层级的最后面,不会混在正常河流中间。
2.4.7 影响范围
- 仅影响展示顺序,不影响数据查询、匹配、统计
-1级河流节点是上游数据本来就有的,SORT=999也是上游的值- 代码里没有造节点、没有改归属、没有改 sort,只是按上游的 sort 排序(
sortChildrenRecursively方法) - 前端展示时,用户会看到”-1级河流”在每个流域的最底部
2.4.8 与 PARENT_CODE='-1' 日志的关系
日志中看到的 未找到父节点: PARENT_CODE='-1'(parseFlatJson 第 144-146 行)和 -1级河流 是两回事:
| 概念 | 字段 | 含义 |
|---|---|---|
-1级河流 |
RVNM(河流名称) |
兜底容器节点,存放无法归类到具体子流域的河流,仅影响排序 |
PARENT_CODE='-1' |
PARENT_CODE(父节点编码) |
某些节点的父节点编码是字符串 "-1",在 nodeMap 里找不到,被当根节点处理 |
实际数据中,-1级河流 节点的 PARENT_CODE 指向的是真实父节点(如 812_813),不是 "-1"。而 PARENT_CODE='-1' 的是另一批节点。代码里两者独立处理:
- 名称标记 → 影响排序(sort=999,排最后)
- 父节点缺失 → 影响树结构(变根节点)
2.5 提交记录 b1cfd65
1 | feat: 流域接口返回多根节点 + 新增设备类型查询接口 + 缓存自愈 |
2.5.1 改动文件(3 个)
| 文件 | 改动 | 说明 |
|---|---|---|
TreeSelectorService.java |
+16/-8 | 6 个流域接口签名改为 R<List<TreeNode>>,新增 2 个设备类型方法 |
TreeSelectorController.java |
+32/-8 | 对应端点签名同步改,新增 2 个设备类型端点 |
TreeSelectorServiceImpl.java |
+200/-58 | 多根处理逻辑 + 缓存自愈 + 设备类型查询实现 |
2.5.2 改动内容
1. 流域接口多根返回(破坏性变更)
6 个接口从 R<TreeNode> 改为 R<List<TreeNode>>:
getRiverBasinTreegetTree(type=basin 时)stationTreeByBasinequipmentTreeByBasinstationTreeFilteredByBasinequipmentTreeFilteredByBasin
去掉 RiverBasinTreeUtil 的虚拟根(”所有流域”),7 个真实根流域直接以数组返回。带 rvcd 时返回单元素 list,不传 rvcd 返回多根(过滤空根)。
行政区侧 4 个接口保持 R<TreeNode> 不变。
2. 新增设备类型筛选接口
GET /equipmentTypesByRegion— 按行政区获取过滤后的设备类型列表(去重)GET /equipmentTypesByBasin— 按流域获取过滤后的设备类型列表(去重)
参数跟对应的过滤接口一致,不传参返回全量。内部复用已有的过滤逻辑,从结果树中提取 queryChild.eqtp 去重返回。
Service 返回 List<String>,Controller 包装 R,符合规范。
3. 缓存自愈
getRegionTreeFromApi:调完第三方接口后顺手写回 Redis(GDSW_AREA_TREE)fetchBasinJsonStr:调完第三方接口后顺手写回 Redis(GDSW_RIVER_B)- 写缓存独立 try-catch,Redis 挂了不影响主流程
- 数据格式跟 BasicDataTask 一致(gzip 压缩)
2.5.3 性能数据
| 接口 | 耗时 |
|---|---|
| equipmentTreeFilteredByBasin | ~330ms |
| equipmentTypesByRegion | ~1071ms |
| equipmentTypesByBasin | ~279ms |
2.5.4 前端注意
- 流域侧 6 个接口的
data从对象变成数组,需要适配 - 行政区侧 4 个接口不变
- 设备类型接口不传参即可拿到全量类型列表
图 2-1:6/2 接口对接全景——前端适配 + 性能特征 + 提交清单
2.6 6/2 经验总结
[!tip] 三个”清晰”
- 接口签名变化要清晰——
R<TreeNode>→R<List<TreeNode>>是破坏性变更,必须先 commit 不 push、让前端确认后再 merge- 接口返回格式要清晰——
List<String>vsR<List<String>>包装层级要统一- 性能特征要清晰——第一次访问 vs 后续命中要分开标注,方便前端做 loading 提示
[!warning] 三个”独立”
- “设备类型筛选接口”和”流域树接口”是独立的两件事——不要因为它们都跟”设备”相关就合并实现
- “缓存自愈”和”接口签名变更”是独立的两件事——分开 commit 方便回滚
- “负一级河流”和”PARENT_CODE=’-1’”是两个独立的概念——字段含义不同、代码路径不同,不要混用
三、6 月 3 日:5 个数据地雷探查
3.1 起点:今天的工作不是写功能
今天的工作不是写功能,而是 **”探路”**——把数据归集模块里几条看起来”理所当然”的东西扒开看了一遍。起因是一个简单的问题:「gdsw 远程库里到底哪张表才是组织架构?」一路追下去,连带把跨数据源查询机制、计划文档与代码不一致、equipmentTypes 接口的近重复值、公司表里的脏数据全部牵了出来。
[!abstract] 今日五个核心发现
- 组织架构只有
bs_sw_cy_dh_company一张表,且用 邻接表 + materialized path 双表示- “跨数据源 join” 实际是 Java 内存里两次查再拼,MySQL 层从来没真正跨过库
- 计划文档写的是
@DS("water"),代码里却是@DS("slave")——本地测不出差异因为两者同库/equipmentTypes返回 38 个唯一值里至少有 6-7 组语义重复,DISTINCT解决不了字典污染- 公司表里一堆区县水文中心 同名两个 ID:一个雪花 ID、一个 UUID,历史迁移没去重
下面逐个展开。
3.2 发现 1:组织架构表 bs_sw_cy_dh_company
最初的问题是:”带组织架构的表” 在 gdsw 远程库到底有几张。结论很干脆:只有一张,叫 bs_sw_cy_dh_company,528 行,32 个根节点。
它的核心字段设计是典型的 “邻接表 + 物化路径” 双模式:
1 | -- 关键字段 |
PARENT_ID 用来查”我的直接孩子”——WHERE PARENT_ID = ? 一刀就完,简单。TREE_CODE 用来查”我的所有后代”——WHERE TREE_CODE LIKE ',1813818490682961922,%',避免递归 CTE。两个一起冗余,写入时要保证一致性,但查询非常爽。
3.2.1 根节点与水文业务主线
根节点是 广东省水文厅(ID = 1813814710436458497),向下分两支:
- 厅内职能处室:办公室、规计处、防御处、调度处、人事处……
- 流域 + 直属单位:东江/西江/北江/韩江 4 个流域管理局,加上广东省水文局、广东省水利水政监察局、广东省水科院等
我重点扒了 水文业务这条主线——PARENT_ID = 1813818490682961922(广东省水文局)下面挂了:
- 局内的现代化建设规划办、十五五规划办、科创办
- 12 个水文分局:深圳、广州、惠州、肇庆、韶关、汕头、佛山、江门、梅州、湛江、茂名、清远
- 每个分局再往下挂区/县水文中心和具体测站,比如广州分局下面有番禺、增城、从化、黄埔水文中心,惠州分局下面有博罗、惠东水文中心,再下面才是麒麟咀、太平场、三善滘这种具体站点
3.2.2 谁会引用这张表
| 表.字段 | 关系 | 备注 |
|---|---|---|
bs_sw_cy_dh_equipmentb.ATCUNIT_ID |
真外键 | 字段注释直接写”隶属行业单位 ID(所属组织架构 ID)” |
bs_sw_cy_dh_station.ATCUNIT |
字符串 | “隶属”单位,存的是 NAME 不是 ID |
bs_sw_cy_dh_station.ADMAUTH |
字符串 | “信息管理”单位,存的是 NAME 不是 ID |
bs_sw_cy_dh_station.LOCALITY |
字符串 | “交换管理”单位,存的是 NAME 不是 ID |
最后一句尤其要命:测站表存的是单位名字符串,一旦公司表里同名节点出现(见发现 5),join 出来就是笛卡尔积。
[!info] 双模式设计的取舍
- 邻接表(PARENT_ID):写起来简单(新增/删除只动一个字段),但查子树要递归 CTE
- 物化路径(TREE_CODE):查子树一句 LIKE 搞定,但写入时要维护整条路径
- 两者冗余:写入时要保证一致性(应用层或 trigger),但查询性能最佳
3.3 发现 2:所谓”跨数据源查询”到底是怎么实现的
用户问:”数据归集里的树是怎么跨数据源查询的?stbprp 表明明在另一个数据源啊?”
[!warning] 反直觉但正确的答案
MySQL 根本不支持跨库 JOIN(除非用 FEDERATED 引擎,而项目没启用)。所以 “跨源查询” 根本不是数据库层做的,而是 应用层分两次 SQL 各查一次,然后在 Java 内存里按 STCD 拼起来。
3.3.1 机制要点
mapper 的注解策略:
1 |
|
注解决定了 mapper 调用走哪个 DataSource,底层是 [[baomidou-dynamic-datasource]] 的 AOP 切换。也就是说每个 mapper “绑死”了它的数据源。
两步查 + 内存拼:
1 | // 第一次查:去 ysq 库捞测站 |
**拼接键就是 STCD**(测站编码)——这是两个库唯一稳定的共识字段。
3.3.2 隐藏成本
第一次返回 N 条,第二次的 IN (...) 列表长度就是 N。MySQL 的 max_allowed_packet 和优化器对超长 IN 子句的处理能力都是有上限的,N 上千就要警惕。当前看 N 控制在百级别,安全;一旦放开过滤条件,可能要换成临时表 + JOIN 模式。
3.3.3 数据源映射(本地 application-local.yml)
| key | 物理地址 | 用途 |
|---|---|---|
master |
127.0.0.1:3306/gdsw |
主业务库 |
slave |
19.25.36.199:15076/ysq |
水文数据源 |
water |
19.25.36.199:15076/ysq |
本机和 slave 同库 |
slave2 |
另一个库 | 河流数据 getRiverData 用 |
注意 slave 和 water 在本机指向同一个库——这就是下一个发现的引线。
[!tip] 这个模式的隐藏成本
- 不是真正的跨库 JOIN——MySQL 不支持,应用层分两次查
- mapper 跟数据源绑死——
@DS注解决定了 mapper 走哪个库,不能在运行时改IN (...)列表长度有上限——N 太大需要换成临时表 + JOIN- STCD 是唯一共识字段——两个库的其他字段不一致,只能按 STCD 拼
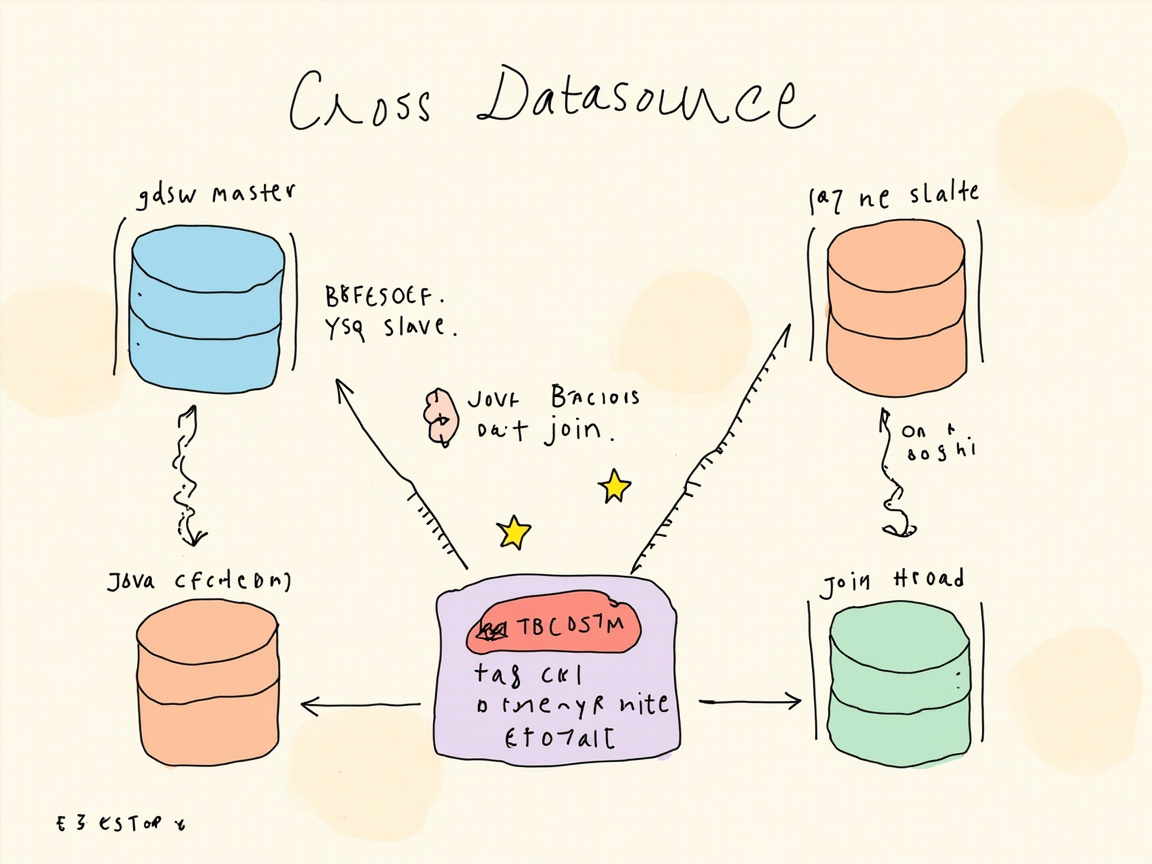
图 3-1:跨数据源查询机制——Java 内存里两次查 + STCD 拼接
3.4 发现 3:计划文档与实际代码不一致
巡查 docs/superpowers/plans/2026-05-21-tree-selector-refactor.md 时发现一个尴尬的对账问题。
文档里第 105 / 138 / 161 行多处明确写:
StStbprpBMapper.java —
@DS("water")
但翻到代码 StStbprpBMapper.java:9 实际是:
1 |
[!danger] 本地测不出来,但生产可能出事
本机配置里slave和water都指向同一个ysq库,所以 怎么测都不报错。但生产/测试环境的 yml 大概率把它们配成不同的物理库(这正是动态数据源存在的意义)。一旦不同,所有跨这个 mapper 的查询都在打错库。
同一文件 TreeSelectorServiceImpl.java 里还有 自己跟自己不一致 的地方:
1 | // line 509 |
两个方法读的是同一类元素表,DS 注解的字符串却不一样。两种可能:
- 故意区分:单条/批量走不同物理库做读写分离。如果是这样,应该有注释说明。
- 历史遗留:refactor 时一处改了一处没改。
需要去查生产 yml 来确认,但无论是哪种,当前注解和文档一致性是 0,得统一。
[!warning] 这种”本地测不出但生产出事”的 bug 最危险
- 本地测不出——
slave和water同库- CI 测不出——CI 通常也用本地 yml
- 生产才会暴雷——但生产环境又复现困难
- 修起来简单——改注解 + 改文档,但找起来困难——没人会怀疑
@DS注解
3.5 发现 4:/dataCollection/equipmentTypes 接口的近重复污染
接口实现非常简单:
1 | QueryWrapper<TreeEquipment> wrapper = new QueryWrapper<>(); |
就一个 SQL 层的 DISTINCT。问题来了:
- 接口实际返回 38 个唯一 EQTP
- 直查数据库
SELECT DISTINCT EQTP FROM ...是 41 个 - 差的 3 个里包括 ADCP、流速仪,还有一个待确认
差 3 个本身不大,但深挖 38 个里的内容才是真正的雷:至少有 6-7 组是语义重复(字面不同但显然同种设备)。
3.5.1 近重复实例
HADCP-水平式ADCPvs水平式ADCP——带不带产品前缀在线HADCPvs在线H-ADCP——一个连字符之差FWQ-浮子水位计vsFWG-浮子水位计vs浮子式水位计——三种命名混杂BWG-气泡水位计vs气泡式水位计——编码版 vs 通用版水质自动监测设备vs水质自动监测站——“设备”和”站”在数据录入员脑子里是一回事雨量计vs翻斗式雨量计——一个泛指一个具体5探头非接触式雷达/4探头非接触式雷达/单探头非接触雷达/多探头固定式雷达——这组可能真的不同,需要业务确认
[!question] 为什么 DISTINCT 救不了
DISTINCT是字节级比较,它看"在线HADCP"和"在线H-ADCP"是两个不同字符串,没办法。要解决必须 在数据层(不是查询层)做归一化——一张EQTP -> canonical_name映射表,或者干脆做受控字典,禁止录入员自由填。
前端拿到这 38 个值往下拉框一塞,用户面对 HADCP-水平式ADCP 和 水平式ADCP 两个选项时怎么选?这是个长期会污染前端 UX 的小坑。
3.6 发现 5:公司表脏数据——同名节点两个 ID
最后一个发现是无意中扒出来的。在看广州水文分局(PARENT_ID = 1813821005054963713)下面的孩子时,发现 两个「增城区水文中心」并列:
1 | ID = 1876832803289645057 ← 雪花 ID,19 位数字 |
继续扫了一遍,类似情况遍地都是:番禺、增城、从化、黄埔、南沙、惠东、博罗、龙门、紫金、东源、龙川、五华、兴宁、廉江、雷州、吴川、化州、高州、信宜、新丰、翁源、仁化、浈江、乐昌、揭西、惠来、陆丰、湘桥……几乎所有区县级水文中心都同时存在两个节点。
[!bug] 根因猜测
历史数据从老系统迁移过来用的是 UUID 主键;新系统启用后,新建节点用雪花 ID。同步脚本没做去重,结果两套 ID 共存。
3.6.1 下游影响
更要命的是 下游的影响:
- 前端树形选择器按 ID 唯一,但展示按 NAME。用户在树里看到两个一模一样的「增城区水文中心」,根本不知道选哪个。
- 内存里去重时 不能只按 ID,必须按
(PARENT_ID, NAME)联合去重——而且要决策保留哪一个。 - 接发现 1 的伏笔:
bs_sw_cy_dh_station.ATCUNIT存的是 NAME 字符串。如果按 NAME join 公司表,一对二就是笛卡尔积,测站数瞬间翻倍。
[!warning] 这不是”加个 distinct”能解决的
必须从数据治理层面做一次清洗:按(PARENT_ID, NAME)聚合,保留新 ID(雪花),旧 ID(UUID)打软删除标记。同时要审计有没有外键指向旧 ID,指向旧 ID 的要 先重定向再标删,否则会产生悬空引用。
3.7 后续行动
按优先级排:
[!todo] 待办
- 统一 mapper 数据源注解:拉生产/测试的 yml 对一下
slave和water是不是真的同库;如果是,删一个 key;如果不是,决定StStbprpBMapper该指向哪个,并改掉TreeSelectorServiceImpl里 509 行和 544 行的不一致- 同步更新计划文档:
docs/superpowers/plans/2026-05-21-tree-selector-refactor.md里所有@DS("water")改成实际的注解值- 设备类型归一化:为
/equipmentTypes加一张EQTP -> canonical_name映射表,接口返回 canonical 列表;老数据可以保留,但前端不再看到- 公司表去重脚本:按
(PARENT_ID, NAME)聚合,保留雪花 ID,UUID 节点先扫一遍外键引用,无引用直接删,有引用先重定向- 回归测试:所有以上动作做完后,必须跑
/dataCollection/stationTreeFilteredByBasin等接口确认树结构没变
[!quote] 一句话总结
今天没写一行业务代码,但把 5 个”地雷”都标了出来——这种工作的价值不在 PR 行数,而在以后少加几次班。
图 3-2:5 个数据地雷汇总——组织架构、跨源机制、注解不一致、设备类型污染、公司表脏数据
四、跨日总结:三天的工作节奏
4.1 节奏对比
| 日期 | 工作类型 | 产出 | 涉及代码行数 |
|---|---|---|---|
| 6/1 | 改造 + 排查 | 5 个接口、2 个工具方法、3 个文档 | +115 / -57 |
| 6/2 | 对接 + 说明 | 3 个接口、3 个文档 | +48 / -24 |
| 6/3 | 探查 + 待办 | 0 个接口改动、5 个待办、1 个工作记录 | 0 |
**6/1 是”行动日”——大量代码改动和接口上线;6/2 是”收尾日”——写文档、对接前端;6/3 是”反思日”**——不写代码,把隐藏问题挖出来。
4.2 三个”相互纠缠”的主题
回头看,三天的工作其实在反复围绕 3 个主题:
- 接口签名变更:6/1 改了 6 个接口 → 6/2 写对接文档 → 6/3 发现文档和代码不一致
- 数据问题:6/1 发现 148 个孤儿设备 → 6/2 设备类型筛选接口 → 6/3 发现设备类型污染
- 跨源机制:6/1 改造时用
@DS→ 6/2 提交时跟 plan 对账 → 6/3 发现注解不一致
这是耦合的代码基底的必然结果——改一个接口会牵出文档、数据、跨源三个层面的问题。
4.3 三个”应该记住”的经验
[!tip] 经验一:文档与代码同步
计划文档(docs/superpowers/plans/*.md)和实际代码必须保持一致。如果改了代码没改文档,3 天后自己都会忘记当初为什么这么改。建议每次提交都检查一下 plan 里有没有引用到改动的代码。
[!tip] 经验二:数据问题用数据方式解决
148 个孤儿设备 STCD 为空——这种问题应该用 SQL 查 + 数据治理的方式解决,不要试图在代码里”模糊匹配”做补救。代码补救会引入不确定性,让数据问题更隐蔽。
[!tip] 经验三:探查日比编码日更宝贵
6/3 一行业务代码都没写,但挖出的 5 个数据地雷,可能比 6/1 那一波改造更有长期价值。建议每周至少留 1 天做”探查日”,把”理所当然”全部扒开看一遍。
五、资料佐证
5.1 数据库证据
5.1.1 148 个孤儿设备 SQL
1 | -- 查询孤儿设备 |
5.1.2 组织架构表结构
1 | -- 关键字段 |
5.1.3 同名节点双 ID 检测
1 | -- 检测 (PARENT_ID, NAME) 重复 |
5.2 提交记录(commit b1cfd65)
1 | feat: 流域接口返回多根节点 + 新增设备类型查询接口 + 缓存自愈 |
改动文件(3 个):
| 文件 | 改动 | 说明 |
|---|---|---|
| TreeSelectorService.java | +16/-8 | 6 个流域接口签名改为 R<List |
| TreeSelectorController.java | +32/-8 | 对应端点签名同步改,新增 2 个设备类型端点 |
| TreeSelectorServiceImpl.java | +200/-58 | 多根处理逻辑 + 缓存自愈 + 设备类型查询实现 |
commit 关联:
- 6/2 提交 b1cfd65
- 6/1 的 type 字段、6/1 的多根改造、6/1 的性能优化、6/2 的设备类型接口、6/2 的缓存自愈 都在这次 commit 里
5.3 API 验证结果
5.3.1 type 字段链路验证
1 | # 请求 equipmentTreeFilteredByBasin |
返回:
1 | { |
✅ 全部正确。
5.3.2 设备类型接口验证
1 | curl -s "http://localhost:8080/dataCollection/equipmentTypesByBasin" | jq '.data' |
返回 6 个(流域全量):
1 | [ |
5.4 性能数据
| 接口 | 第一次(缓存空) | 后续命中 | 备注 |
|---|---|---|---|
riverBasinTree |
~330ms | ~150ms | DB 直连 |
stationTreeByBasin |
~500ms | ~400ms | 过滤空根 |
equipmentTreeByBasin |
~500ms | ~400ms | 过滤空根 |
equipmentTreeFilteredByBasin |
~330ms | ~250ms | 含过滤 |
equipmentTypesByRegion |
~1071ms | ~800ms | 递归收集 + 去重 |
equipmentTypesByBasin |
~279ms | ~200ms | 流域范围更小 |
getRegionTreeFromApi |
~1500ms | ~500ms | 第一次调第三方 |
stationTreeByRegion |
~1500ms | ~500ms | 第一次调第三方 |
equipmentTreeByRegion |
~1500ms | ~500ms | 第一次调第三方 |
DB 查询次数优化对比:
| 接口 | 改前 | 改后 |
|---|---|---|
stationTreeByBasin no-rvcd 测站查询 |
7 次 | 1 次 |
equipmentTreeByBasin 设备查询 |
7 次 | 1 次 |
7 个根场景下两个接口的 DB 查询总数从 14 次降到 2 次。
5.5 涉及文件清单
5.5.1 后端代码
| 模块 | 路径 | 改动类型 |
|---|---|---|
| API DTO | gdsw-modules/algorithm-plugin-modules/algorithm-plugin-api/src/main/java/com/zny/algorithm/api/dto/TreeNode.java |
新增 type 字段 |
| Service 接口 | gdsw-modules/data-collection-modules/data-collection-api/src/main/java/com/zny/datacollection/api/service/TreeSelectorService.java |
6 个方法签名调整 |
| Service 实现 | gdsw-modules/data-collection-modules/data-collection-starter/src/main/java/com/zny/datacollection/starter/service/impl/TreeSelectorServiceImpl.java |
6 个方法重写 + 抽 fetchBasinJsonStr + 查询优化 + 空根过滤 + 缓存自愈 |
| Controller | gdsw-modules/data-collection-modules/data-collection-core/src/main/java/com/zny/datacollection/core/controller/TreeSelectorController.java |
6 处端点签名调整 |
| 工具类 | gdsw-modules/data-collection-modules/data-collection-starter/src/main/java/com/zny/datacollection/starter/utils/RiverBasinTreeUtil.java |
仅参考,未改动 |
| Mapper | gdsw-modules/data-collection-modules/data-collection-core/src/main/java/com/zny/datacollection/core/mapper/StStbprpBMapper.java |
@DS("water") vs @DS("slave") 待确认 |
5.5.2 数据库表
| 表名 | 用途 | 行数 | 备注 |
|---|---|---|---|
bs_sw_cy_dh_company |
组织架构 | 528 | 邻接表 + 物化路径双模式 |
bs_sw_cy_dh_equipmentb |
设备 | 1813 | 148 个 STCD 为空 |
bs_sw_cy_dh_station |
测站 | 1051 | ATCUNIT 存 NAME 字符串 |
5.5.3 文档
| 文档 | 路径 | 状态 |
|---|---|---|
| 6/1 工作记录 | 项目/数据归集系统/2026-06-01/2026-06-01工作记录.md |
已发布 |
| TreeNode type 字段 | 项目/数据归集系统/2026-06-01/TreeNode-type字段功能.md |
已发布 |
| 树接口流域多根改造 | 项目/数据归集系统/2026-06-01/树接口流域多根改造.md |
已发布 |
| 紫洞设备问题排查 | 项目/数据归集系统/2026-06-01/紫洞设备问题排查.md |
已发布 |
| 6/2 tree 接口对接说明 | 项目/数据归集系统/2026-06-02/tree接口改造对接说明.md |
已发布 |
| 6/2 设备类型筛选接口 | 项目/数据归集系统/2026-06-02/设备类型筛选接口.md |
已发布 |
| 6/2 负一级河流逻辑 | 项目/数据归集系统/2026-06-02/负一级河流逻辑说明.md |
已发布 |
| 6/3 数据归集探查 | 项目/数据归集系统/2026-06-03/2026-06-03记录.md |
已发布 |
| 6/3 提交记录 | 项目/数据归集系统/2026-06-03/提交记录.md |
已发布 |
5.6 外部参考
5.6.1 baomidou-dynamic-datasource
- 官方文档:https://baomidou.com/guides/dynamic-datasource/
- 核心机制:基于 Spring AOP 的
@DS注解 +DataSource注册中心 - 本文引用:[[baomidou-dynamic-datasource]]
- 相关引用:mapper 注解
@DS("slave")决定数据源
5.6.2 MyBatis-Plus
- 官方文档:https://baomidou.com/
- 本文引用:
QueryWrapper/BaseMapper/groupingBy等
5.6.3 MySQL 跨库限制
- FEDERATED 引擎:https://dev.mysql.com/doc/refman/8.0/en/federated-storage-engine.html
- 本文核心结论:MySQL 默认不支持跨库 JOIN,应用层分两次查 + 内存拼是常见做法
5.7 关联博客
- 《树结构选择器:从 Redis 到直连数据库的架构重构》——5/21 改造基础
- 《Spring Boot 多数据源开发实践:从踩坑到解决》——多数据源原理
- 《水文数据均值对比查询 Bug 修复全记录》——同项目 bug 修复风格
- 《广东水文项目问题排查实录 2026 年 3 月 19 日》——同项目排查风格
六、经验总结与结语
6.1 三个”不一样”
[!tip] 工作节奏不一样
6/1 是行动日,6/2 是收尾日,6/3 是反思日。三天里只有 6/1 写代码,但 6/3 挖出的问题可能比 6/1 那一波改造更有长期价值。不要把每天塞满编码。
[!tip] 问题深度不一样
6/1 的”148 个孤儿设备”是数据问题,6/3 的”5 个数据地雷”是治理问题。前者改一行 SQL 就能修,后者需要跨部门协作。看清问题的层级比急着解决更重要。
[!tip] 文档价值不一样
6/2 的 3 篇对接文档(接口对接、设备类型、负一级河流)让前端和上游数据问题有了”单一可信源”。好的文档不是重复代码,而是解释”为什么这样设计”。
6.2 三个”应该坚持”
[!tip] 坚持写工作记录
6/1 ~ 6/3 三天每天都有工作记录,6/1 的 8 个章节、6/2 的 6 个章节、6/3 的 7 个发现,都有完整的证据链。未来的你会感谢现在的自己。
[!tip] 坚持用数据说话
148 不是拍脑袋,是SELECT COUNT(*)查出来的;7 个根流域不是猜的,是SELECT COUNT(DISTINCT PARENT_ID)算出来的。没有数据支撑的结论都是空话。
[!tip] 坚持做”探查日”
每周至少留 1 天做”探查日”,把”理所当然”全部扒开看一遍。这种工作的价值不在 PR 行数,而在以后少加几次班。
6.3 结语
三天三件事,看上去是分立的几个任务,实际上是数据归集系统从”能跑”到”跑得对”的一次集中检视。6/1 的改造让它跑得更快,6/2 的文档让它跑得更稳,6/3 的探查让它跑得更对。
下一个迭代的目标很明确:把 6/3 那 5 个待办逐个落地——统一 mapper 注解、同步计划文档、设备类型归一化、公司表去重、回归测试。到那时,这套系统才真正称得上”production-ready”。
如果你也在做类似的多数据源、多端点的前后端集成,希望这篇三天实录能给你一些参考。代码和文档都在文末的资料佐证里,欢迎对照复现。
—— 写于 2026 年 6 月 3 日深夜,把 5 个地雷都标完了