树结构选择器:从 Redis 到直连数据库的架构重构
数据归集系统的树结构选择器是前端高频调用的核心接口。原本从 Redis 读取 GZIP 压缩的全量 JSON 数据,每次请求都要解压 7MB 数据再内存过滤。本文记录了将其改造为直连数据库的完整过程,包括多数据源配置、第三方 API 对接、以及踩坑经验。
🎧 文章导读
🎵 背景音乐
前言
在水文监测数据归集系统中,树结构选择器(行政区→测站→设备三级联动)是前端页面的核心交互组件。原有实现统一走 Redis 缓存——第三方系统把数据同步到 Redis,后端从 Redis 取 GZIP+Base64 压缩的全量 JSON,解压后在内存中遍历过滤。
这套方案在测试和生产环境跑得通,但在本地开发时问题暴露得非常明显。
重构动机:三个核心痛点
痛点一:本地环境 Redis 缺数据
开发机上没有跑同步任务,Redis 里要么没 key 要么数据过期了,导致三个树接口全部返回空。每次想调试一个和选择器相关的功能,都要先想办法往 Redis 里灌数据,或者连上测试环境的 Redis。
痛点二:每次请求解压 7MB 全量数据
Redis 里存的是整个表的 JSON 压缩包,哪怕前端只想查一个测站下的几台设备,后端也得把全部设备数据解出来再遍历。内存开销和 GC 压力都不小。
1 | // 改造前的核心模式:Redis → 解压 → 遍历 |
痛点三:数据新鲜度依赖外部同步任务
Redis 里的数据什么时候更新、更新失败怎么办,后端完全不知道,只能被动等待。遇到数据不一致的 bug,排查链路要跨两个系统。
改造方案:直连数据源
选择直连数据源的理由很直接:数据源本身就在那里——water 库里有完整的测站表,gdsw 库里有完整的设备表,第三方 API 能返回行政区树。既然源头可用,为什么还要绕 Redis 一圈?
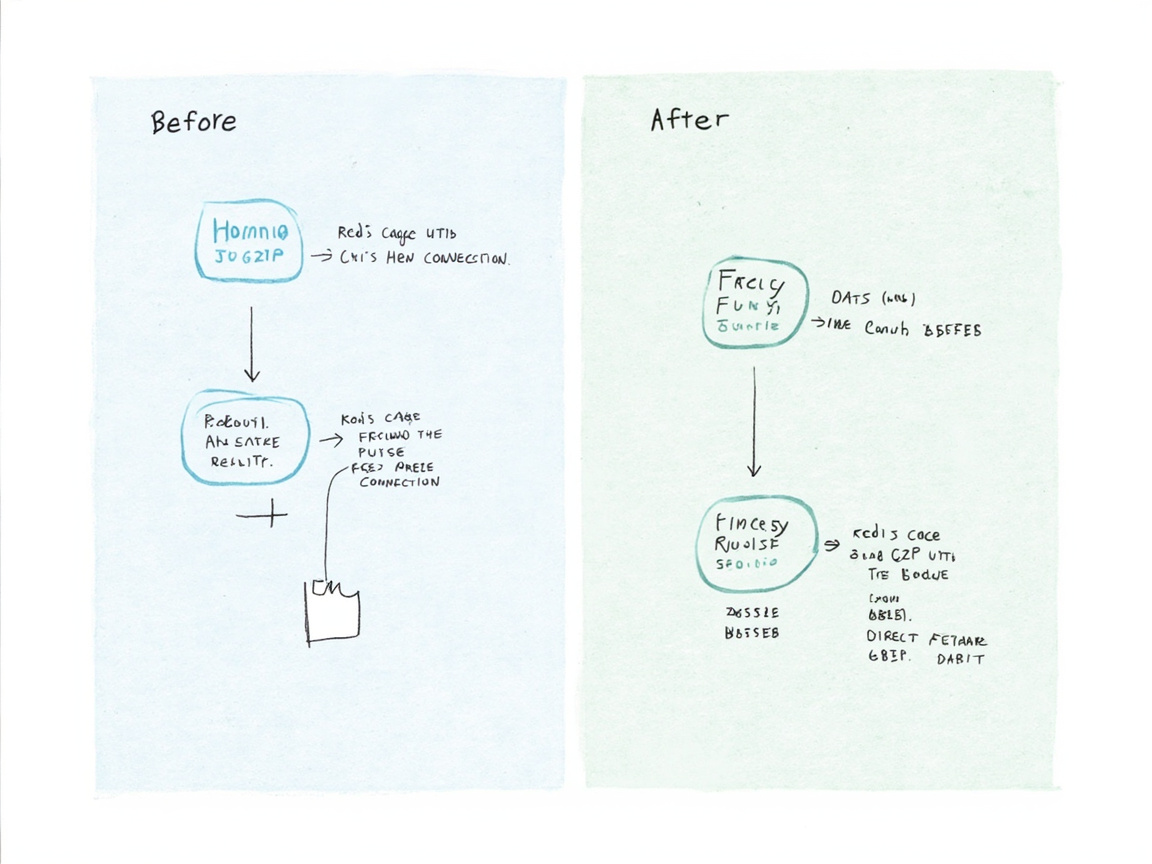
图1:改造前(Redis 全量缓存)vs 改造后(直连数据库)的数据流对比
改造后的数据流大幅简化:
1 | 第三方API water数据库(ysq) gdsw数据库 |
核心实现
Step 1: 行政区树——第三方接口直连
行政区数据来源于第三方门户系统的 API,改造后直接调用第三方接口,配合网关签名认证:
1 | // 网关签名:SHA256(timestamp + token + nonce + timestamp) |
Step 2: 测站列表——数据库查询 + 前缀匹配
测站表在 water 数据库的 st_stbprp_b 表中。核心挑战是前端传的行政区编码(12 位)和数据库存的编码(6 位)长度不一致:
1 | // 去掉尾部零,提取有效前缀 |
新建了 StStbprpB Entity 和 StStbprpBMapper,Mapper 上用 @DS("water") 注解切换到 water 数据源。
Step 3: 设备列表——精确查询
设备表在 gdsw 主库,按测站编码精确匹配:
1 | QueryWrapper<TreeEquipment> wrapper = new QueryWrapper<>(); |
Step 4: 流域树——平铺转树形
新增 /riverBasinTree 接口,从第三方 API 获取平铺流域数据,通过 RiverBasinTreeUtil 工具类构建树形结构:
1 | // 四阶段算法:建索引 → 挂父子 → 排序 → 计数 |
多数据源配置
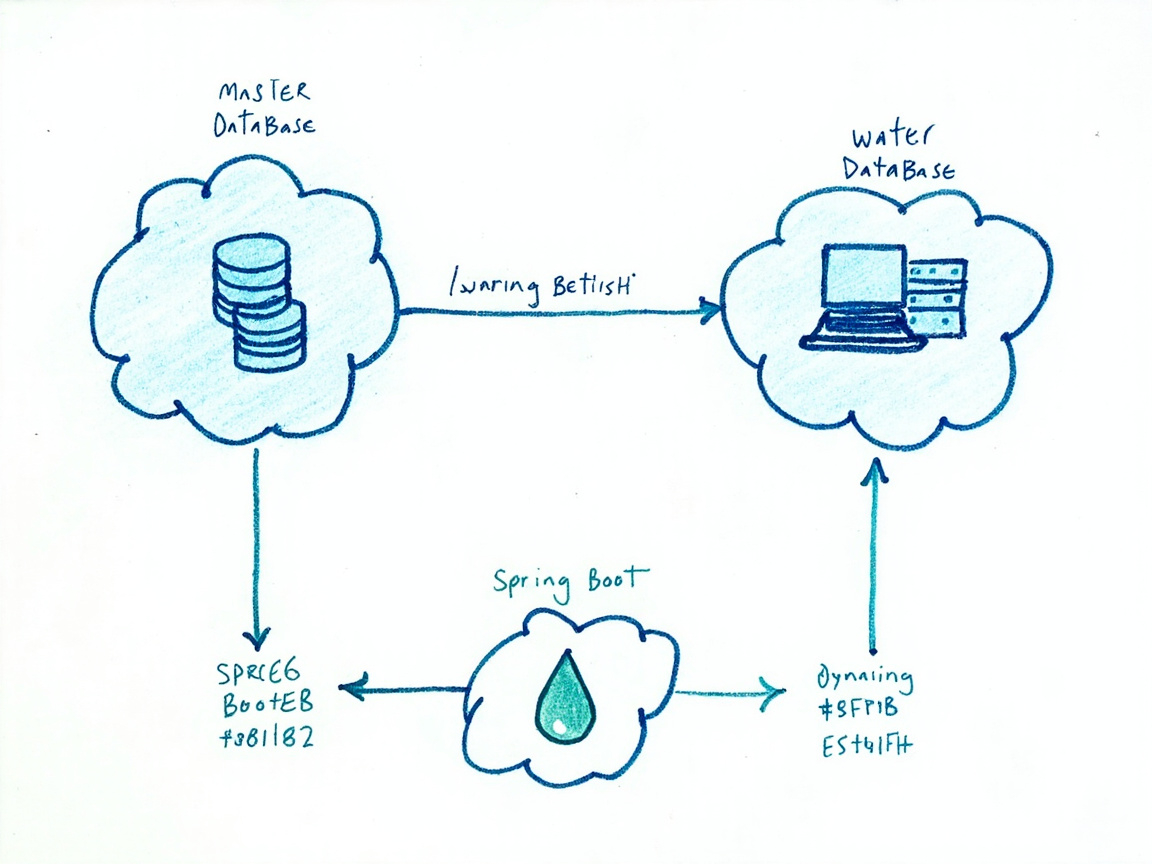
图2:多数据源配置架构,master 和 water 数据源切换
项目使用了 dynamic-datasource(Baomidou 的多数据源框架),新增 water 数据源只需在配置文件中添加:
1 | spring: |
踩坑记录
Bean 名冲突
algorithm-plugin-starter 模块已有 EquipmentBMapper,新建同名 Mapper 导致 ConflictingBeanDefinitionException。解决方案:改名为 TreeEquipmentMapper。
教训:多模块项目里新建 Mapper 之前,先全局搜索是否已有同表 Mapper。
认证头类型错误
流域树接口最初复用了行政区树的 generateGatewayHeaders() 方法,但实际需要 X-Auth-Data + X-Auth-Appid 的 RSA 加密认证头。两种认证机制完全不同,不能混用。
教训:调用第三方 API 时,不能假设所有接口使用相同的认证方式。
特殊字符密码
water 数据源密码含特殊字符(}&S^!),在配置文件里需要加引号保护。
接口变更总览
| 接口 | 路径 | 改造前 | 改造后 |
|---|---|---|---|
| 行政区树(缓存) | GET /regionTree |
Redis | 保持不动 |
| 行政区树(直连) | GET /regionTreeFromApi |
不存在 | 新增 |
| 测站列表 | GET /stationTree?addvcd=xxx |
Redis 全量解压 | QueryWrapper 查 water 库 |
| 设备列表 | GET /equipmentTree?stcd=xxx |
Redis 全量解压 | QueryWrapper 查 gdsw 库 |
| 流域树 | GET /riverBasinTree |
不存在 | 新增 |
经验总结
这次重构的核心收获是架构决策要随着系统演进重新评估。项目初期的”全量缓存到 Redis”方案确实是最快跑通的选择,但半年后回头看,数据源本身就在数据库里,中间加一层 Redis 反而增加了复杂度。
关键要点:
- 当发现自己在为缓存维护同步任务、处理过期问题、mock 本地数据时,就该想想是否可以”跳过中间层”
- 多数据源项目新建 Mapper 前先全局搜索,避免 Bean 名冲突
- 调用第三方 API 前务必确认实际认证要求,不能凭经验假设
- 特殊字符密码在配置文件中要加引号保护
本文涉及代码已提交到 master-b_sp_20251216-delDec 分支。