pass_user 字段同步 + 人员列表联动 + 代码审查:折中方案与前端 import 来源踩坑
导读
今天三个主题:钉钉同步补 pass_user 的手机号和部门(折中方案)、人员列表页面部门下拉按园区联动(前端 import 来源同名坑)、代码审查记录(已合并改动)。其中最值得记录的是折中方案的取舍——为什么”换部门同步”主动放弃,以及前端 import 同名函数指向不同后端接口这种隐蔽问题。
🎧 文章导读
🎵 背景音乐
前言
钉钉同步的核心链路跑通后,pass_user 还缺两个字段:手机号、部门。看似简单的同步需求,挖下去发现要做完”完美方案”得改 3 处,且 admin 重建组织关系是拦路虎。
同时前端人员列表部门下拉一直不能按所选园区联动——表面看是后端 bug,深入 trace 发现是前端 import 来源错了:organizationTree 同名函数在不同文件,调的是不同后端接口。
图1:折中方案示意图
Part 1:折中方案选型
完整方案要改 3 处,其中 admin 重建最麻烦
要让”已有钉钉人员换部门”也同步到 pass_user,需要打通三处:
- admin 侧重建组织关系 —
UserSyncServiceImpl第 225 行至今是个TODO:钉钉用户换部门时,sys_user_organization根本没被更新 - paging 查询把 org_id 带出来 — pass_user 同步是重新分页查 sys_user,而
listByConditionExtSELECT 里没有 org_id - pass_user 加 UPDATE 分支 — 原方法只有 INSERT
第 1 处是拦路虎:admin 的组织重建涉及软删旧关联、批量重建,还要顾及用户列表页等共用 listByConditionExt 的逻辑,改动面大、容易碰坏别处。
为什么选择折中
评估下来:手机号更新只差第 3 处(1 处),部门更新要三处全做。考虑到换部门是低频事件,而 admin 重建的风险和工作量都不划算,最终选择:
- ✅ 手机号更新(已有人员改号 → 同步)
- ✅ 新人部门首次写入(首次进 pass_user 就带上 org_id)
- ✅ 顺带补齐历史空 org_id
- ❌ 已有人员换部门 → 不同步(接受这个误差,留到以后再做 admin 重建)
单位/部门的关系:前端搞定,后端只存一个 org_id
排查中发现页面上”所属部门”显示成两级(如 西部检修试验分公司 > 电气一次检修部),一度以为要存两个字段。查清楚后发现:
sys_organization是树结构(有parent_id),部门是子级、公司是父级- 这个两级显示是前端做的——后端只返回
org_id,前端getParentNames(staffList.vue:2630)沿parent_id往上爬拼出来 - 所以
pass_user只需存部门 org_id(子级),单位自动从树推出来,不用加列、不用单独同步单位
Part 2:实现
改动 1:admin 让 paging 带出部门 org_id
UserMapperExt.xml 的 listByConditionExt 仿照已有的 park_id 子查询,加一个把用户部门 org_id 带出来的子查询。关键是”怎么取到部门那行”——钉钉用户的 org 是 [部门, 公司],取 parent_id 非空的子级就是部门(公司是顶级、parent 为空):
1 | /* 部门 org_id:钉钉用户 org 为 [部门, 公司],取 parent_id 非空的子级 */ |
这里用聚合子查询(每用户聚出一行)而不是直接 JOIN,是为了避免一个用户有多条 org 关联时把主查询的行数撑爆——这是借鉴旁边 park_id 子查询的成熟写法。
改动 2:through 加 UPDATE 分支 + INSERT 补 org_id
PassUserServiceImpl.synSysUserToPassUser 原来只有”新人 INSERT”。改成 INSERT + UPDATE 两条路,并且 UPDATE 加了脏检查——只有手机号变了、或 org_id 需要补,才进更新队列:
1 | String newPhone = EncryptionUtils.phoneEncryptToHex(user.getPhone()); |
[!warning] 为什么必须做脏检查
如果无脑把所有关联用户都标distSyncStatus=PENDING,每次钉钉同步都会触发全员分区/设备重同步——哪怕没一个人变。脏检查确保只有真正变化的才重标 PENDING。
reviewer 建议加 @Transactional —— 不能加
code review 时有人建议给 synSysUserToPassUser 加 @Transactional 保证原子性。这条不能采纳:该方法在 for 循环里调了 Feign userClient.paging(),整方法加事务等于在数据库事务里夹网络 IO——事务在等 HTTP 返回时一直占着连接和锁,是明确的反模式。真要原子性,得把两次 batch 写抽到独立的事务方法里,但不划算(这方法本身可重入、失败下次自愈)。
测试与验证
由于 dev 库没有真实钉钉用户,用 POST /sync/mockDingUserSync 注入测试用户(部门用真实存在的 136541718 电气一次检修部)。三条路径实测全绿:
| 路径 | 验证 |
|---|---|
| INSERT 新人 | pass_user 写入 phone + org_id=136541718(以前会是空) |
| UPDATE 改手机号 | phone 跟着变、distSyncStatus=PENDING、update_time 刷新 |
| UPDATE 补空 org_id | 真实用户”蓝文文”org_id 从 null → 61955385(外部厂家) |
折中方案的代价
这次的核心决策是**主动放弃”换部门同步”**——不是做不到,是代价(admin 组织重建)不划算。换部门低频,而手机号变更、新人入库是高频场景,折中方案用最小改动覆盖了主要收益。
后续如果业务确实需要”换部门也同步”,回头补 admin 侧的 UserSyncServiceImpl:225 组织重建即可,pass_user 这边的 UPDATE 分支已经 ready。
Part 3:人员列表部门下拉按园区联动
需求
便捷通行”人员列表”页面(/through/staffManage/staffList/staffList)搜索栏有”园区”+”部门”两个筛选条件。
- 原状:选了园区,部门下拉显示的是当前登录人园区绑定的公司(后端写死
baseUser.getParkId()),与所选园区无关 - 需求:搜索栏选了园区 X,部门下拉只显示 X 绑定的公司
调用链(trace 到 mapper)
1 | 前端 allocateOrg() |
关键写死点:OrganizationServiceImpl#getCurParkOrgTree 第 338 行
1 | parkOrganizationDTO.setParkId(baseUser.getParkId()); // 忽略前端传入 |
关键踩坑:前端同名 organizationTree 指向两个不同的后端接口
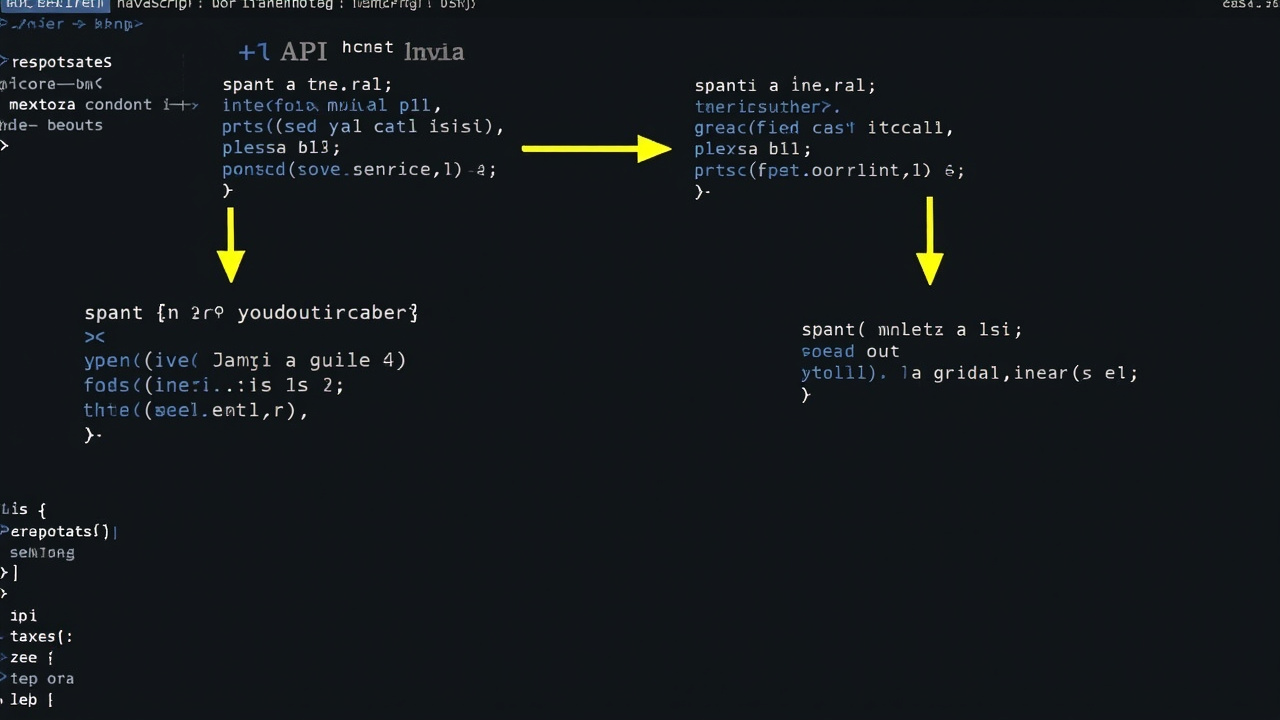
图3:前端 import 来源
[!warning] 同名 organizationTree,指向两个不同的后端接口
前端有两个organizationTree函数,名字相同但调不同后端接口:
import 来源 后端接口 方法 行为 @/api/common/organization/selectCurParkOrgTreegetCurParkOrgTree按园区绑定过滤 @/api/system/user/user/organization/organizationTreeselectOrganizationTree按用户权限返回全量,不读 parkId
staffList.vue:1276原本 import 的是 user.js 那个,所以即便后端改好了getCurParkOrgTree,传 parkId 也完全不生效——前端压根没调那个接口,照返回权限内的全量组织树,表现为”选了番禺基地还返回一大堆数据”。
最终改动(3 处)
1. 后端:parkId 兜底
OrganizationServiceImpl.java#getCurParkOrgTree 第 338 行:
1 | // 原 |
2. 前端:allocateOrg 参数化
staffList.vue:
1 | // 原 |
搜索栏的 watcher 早已 this.allocateOrg(val) 传参,这处一接上就联动。空值传 {} → 后端兜底当前登录人园区。
3. 前端:import 来源修正
staffList.vue:1276:
1 | // 原 |
验证
sys_park_organization 查询确认番禺基地(parkId = 284cd7570daf5d1ca8e121bc025f7a02)绑定 5 个公司:
| org_id | 名称 |
|---|---|
| 136602494 | 西部检修试验分公司 |
| c5e47144b0e514223df3947bfcd2f948 | 园区总部 |
| 59900345 | 公司本部 |
| 59969486 | 信息通信分公司 |
| b9546c9600e99e789d7d86313c4941d6 | 园区二级部门 |
验证步骤:重启 admin-service → 前端刷新 → 搜索栏选番禺基地 → 部门下拉应正好是这 5 个。
已知限制
- 新增弹窗切园区不联动:
changeParkId(staffList.vue:2005)仍是空实现 - 编辑回填:
updateButton不调allocateOrg(res.parkId) orgTreeDataThree共用:搜索栏、新增弹窗、钉钉用户弹窗共用同一个orgTreeDataTwo变量,互相影响
图2:代码审查表
Part 4:代码审查记录
1. UserMapperExt.xml — listByConditionExt 补部门 org_id
审查结论:✅ 正确
parent_id IS NOT NULL AND parent_id <> ''正确区分了”部门”和”公司”delete_flag = '0'在 WHERE 和 JOIN 两处都过滤MIN(uo2.org_id)处理一人多部门,取一个,注释写了一人一部门,MIN 只是兜底- LEFT JOIN 意味着没有部门的用户 orgId 返回 null,不会丢失用户行
2. PassUserServiceImpl.java — synSysUserToPassUser 补 orgId + UPDATE 分支
审查结论:✅ 正确
- Map 替换 List:查找从 O(n) 降到 O(1)
- filter sysUserId 非空:排除了手动创建和访客的 pass_user
- add 分支 setOrgId:依赖 admin 端 mapper 改动返回的 orgId 字段
- update 分支:
if (StringUtils.isBlank(existing.getOrgId()))只补空值,不会覆盖已有的 orgId,安全
注意点:
listByCondition(queryDTO)加载全量 pass_user 到内存建 Map,数据量大时注意内存- update 分支没同步 real_name 和 face_pic,如果后续需要可以加,当前不改没问题
经验总结
折中方案是工程实践的核心
“换部门同步”看似只是”再加一行代码”,深入追下去要做 3 处改动,其中 admin 重建是拦路虎。主动放弃低频场景比”硬上完整方案”更专业——这要求对业务频率、改动风险有量化判断。
前端 import 同名函数的隐蔽性
organizationTree 这个名字很常见,但不同文件里的同名函数调不同后端接口。这正是全局规则 [2026-06-11] Plan review 必须 trace 完整调用链 的延伸:不仅要 trace 到 mapper XML,前端 import 的真实指向也要落实。
@Transactional 不是万能药
synSysUserToPassUser 加 @Transactional 看似合理,但事务 + Feign 网络 IO = 反模式。事务持有连接和锁,HTTP 调用阻塞 → 连接占用久 → 整个系统跟着慢。
折中方案要有”回头补”的路径
放弃”换部门同步”时,明确记录”回头补 admin 侧 UserSyncServiceImpl:225 组织重建即可”——这不是甩锅,是给未来的自己留路标。代码 + spec + obsidian 笔记三者对齐,未来才不会忘了为什么放弃。
关联
- [[2026-06-15 工作记录]]
- [[代码审查记录]]
- [[钉钉同步pass_user字段/功能设计与实现]]
- [[人员列表部门按园区联动]]